
상품선물에 그래프를 입혔다 — 만기별 가격 관계를 학습하는 캘린더 스프레드 AI
같은 원유인데, 3월물과 6월물 가격이 왜 다를까? 그 차이를 '그래프'로 배워서 이익을 내는 새로운 방법이 나왔습니다.
들어가며: 휘발유 값이 오르면, 모든 휘발유가 똑같이 오를까?
여러분이 주유소에서 기름을 넣을 때, 휘발유 값은 오르내립니다. 그런데 같은 '휘발유'라도 납기(만기)가 다른 선물 계약은 가격 움직임이 다릅니다. 예를 들어, 전쟁이 터지면 당장 3개월 뒤 납품하는 휘발유 선물은 가격이 치솟지만, 1년 뒤 납품하는 선물은 상대적으로 덜 오릅니다. 시간이 지나면 공급망이 회복될 수 있으니까요.
반대로, 어떤 사건은 3개월 뒤보다 6개월 뒤 가격에 더 크게 반영되기도 합니다. 이렇게 같은 상품이라도 만기가 다르면 가격이 다른 패턴으로 움직인다는 사실은, 투자자에게 아주 중요한 정보입니다.
오늘 소개할 논문은 바로 이 '만기별 가격 관계'를 그래프 신경망(Graph Neural Network)으로 학습해서, 캘린더 스프레드 전략의 수익성을 크게 끌어올린 연구입니다.
무엇이 문제였나: 기존 방법의 한계
상품선물 시장에서 흔히 쓰이는 전략 중 하나가 캘린더 스프레드(Calendar Spread)입니다. 같은 상품의 다른 만기 계약 두 개를 동시에 사고팔아서, 두 가격의 차이(스프레드)에서 이익을 얻는 전략이죠. 주식으로 치면 'pairs trading'과 비슷한 아이디어입니다.
기존에는 이 스프레드를 예측하기 위해 통계적 방법이나 단순한 머신러닝(예: LightGBM)을 썼습니다. 하지만 이런 방법들은 몇 가지 한계가 있었어요:
- 만기 구조를 제대로 반영하지 못함: 같은 원유라도 3월물과 6월물의 가격 역학이 다른데, 기존 방법은 이 차이를 명시적으로 모델링하지 못했습니다.
- 상품 간 관계를 놓침: 원유와 천연가스, 금과 은처럼 서로 관련 있는 상품들의 정보가 서로에게 유용할 수 있지만, 기존 방법은 각 계약을 독립적으로 분석했습니다.
- 복잡한 시장 구조를 단순화: 상품선물 시장은 '상품 → 계약'이라는 계층 구조를 가지고 있는데, 이 구조를 제대로 활용하지 못했습니다.
핵심 아이디어: 상품과 계약을 '그래프'로 연결하다
이 논문의 핵심 아이디어는 놀랍도록 직관적입니다. 상품선물 시장을 그래프(graph)로 표현하자는 거예요.
계층적 그래프 구조
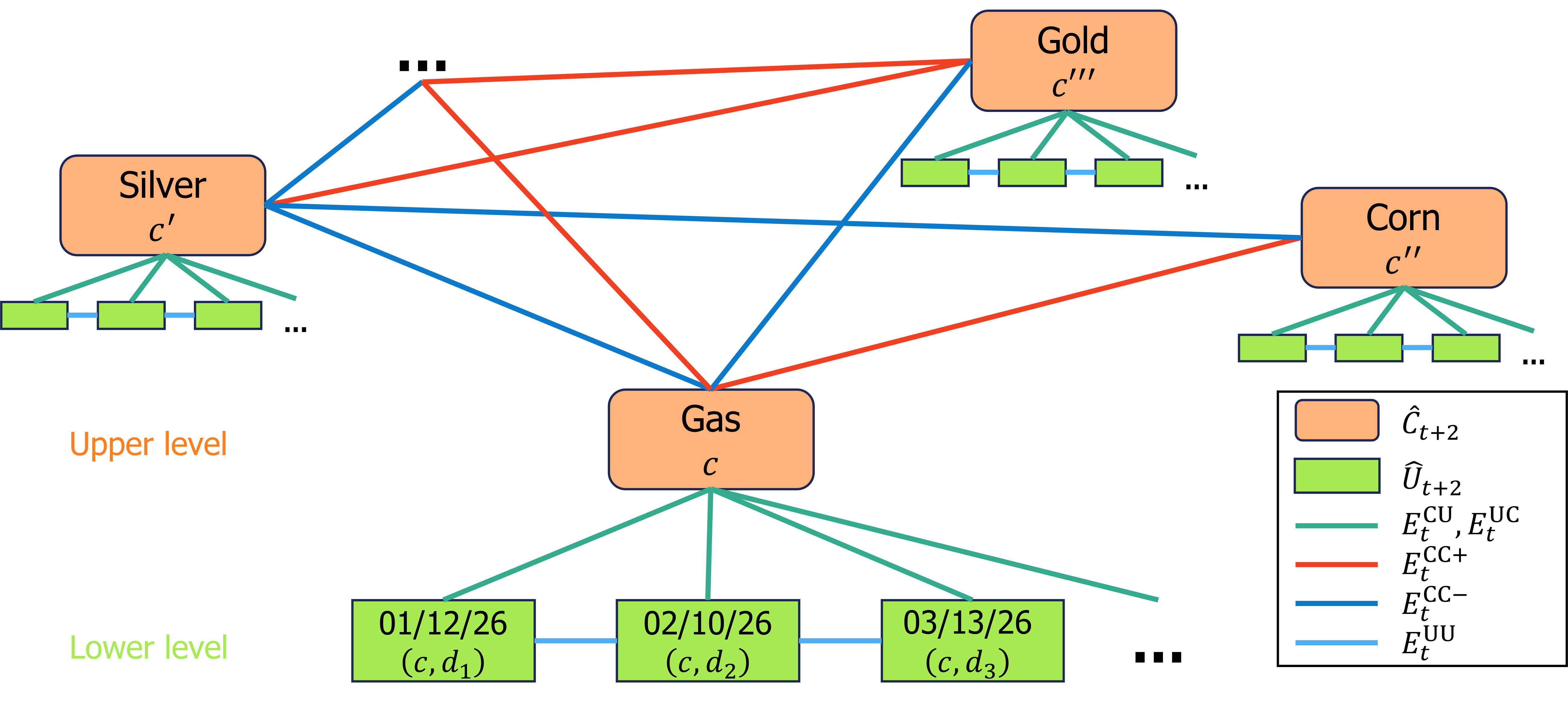
쉽게 말하면 이렇습니다:
- 상위 노드: 원유, 천연가스, 금, 은 같은 '상품(commodity)' 자체가 그래프의 상위 노드입니다.
- 하위 노드: 각 상품에 속하는 개별 선물 계약(예: 2024년 3월물 원유, 2024년 6월물 원유)이 하위 노드입니다.
- 엣지(연결선): 같은 상품에 속하는 계약끼리 연결되고, 서로 관련 있는 상품끼리도 연결됩니다.
이렇게 하면 "원유 3월물과 원유 6월물은 같은 상품이니까 비슷하게 움직이지만, 완전히 같지는 않다"는 정보를 그래프 구조 안에 자연스럽게 넣을 수 있습니다.
TTM(Time-to-Maturity) 정렬: 만기를 맞추는 기술
여기서 가장 독창적인 부분은 만기까지 남은 시간(TTM)을 그래프 안에서 명시적으로 다룬다는 점입니다.
현실에서는 원유 선물은 매월 만기가 있고, 금 선물은 분기별로 만기가 있습니다. 이렇게 상품마다 만기 격자가 다른데, 이 논문은 가상의 '공유 TTM 격자'를 만들어서 만기를 서로 맞추는 Graph Lifting이라는 기법을 제안합니다. 쉽게 말하면, 달력이 다른 두 나라의 일정을 하나의 통일된 달력으로 변환하는 것과 비슷합니다.
Bi-level Convolution: 두 방향으로 정보 흐르기
그래프 위에서 정보가 흐르는 방식도 두 가지입니다:
- 같은 만기 방향: "3월물 원유"의 정보가 "3월물 천연가스"로 흐릅니다. 같은 시점에서 관련 상품끼리 정보를 나누는 거죠.
- 다른 만기 방향: "3월물 원유"의 정보가 "6월물 원유"로 흐릅니다. 같은 상품 내에서 시간 구조의 역학을 포착합니다.
이 두 방향의 정보 흐름을 교차시키면서 모델이 상품 간 관계와 만기 간 관계를 동시에 학습합니다.
결과: 무엇을 알아냈나
이 방법의 성과를 숫자로 살펴보겠습니다. Northwestern 대학 연구팀은 CME(시카고상업거래소)의 상품선물 데이터로 실험했고, 결과는 상당히 인상적입니다.
성과 비교표
| 지표 | HGL (이 논문) | 최고 벤치마크 (LGBM) | 개선율 |
|---|---|---|---|
| 정보 비율 (Information Ratio) | 0.0846 | 0.0432 | +96% |
| 소르티노 비율 (Sortino Ratio) | 0.1241 | 0.0683 | +82% |
| 일일 평균 수익률 | 0.0104% | 0.0065% | +60% |
| 일일 변동성 | 0.1225% | 0.1492% | -18% (낮을수록 좋음) |
| 최대 낙폭 (MDD) | 0.0200 | 0.0389 | -49% (낮을수록 좋음) |
숫자가 좀 많으니 핵심만 정리하면:
- 수익률은 60% 더 높고, 변동성은 18% 더 낮습니다. 즉, 돈을 더 벌면서도 덜 불안정합니다.
- 최대 낙폭(MDD)이 절반 수준으로 줄었습니다. 투자에서 MDD는 '가장 많이 잃었던 순간'을 의미하는데, 이게 절반으로 줄었다는 건 리스크 관리 측면에서 매우 큰 의미입니다.
- S&P 500 대비 정보 비율이 75% 높고, 소르티노 비율은 113% 높습니다.
누적 수익 곡선
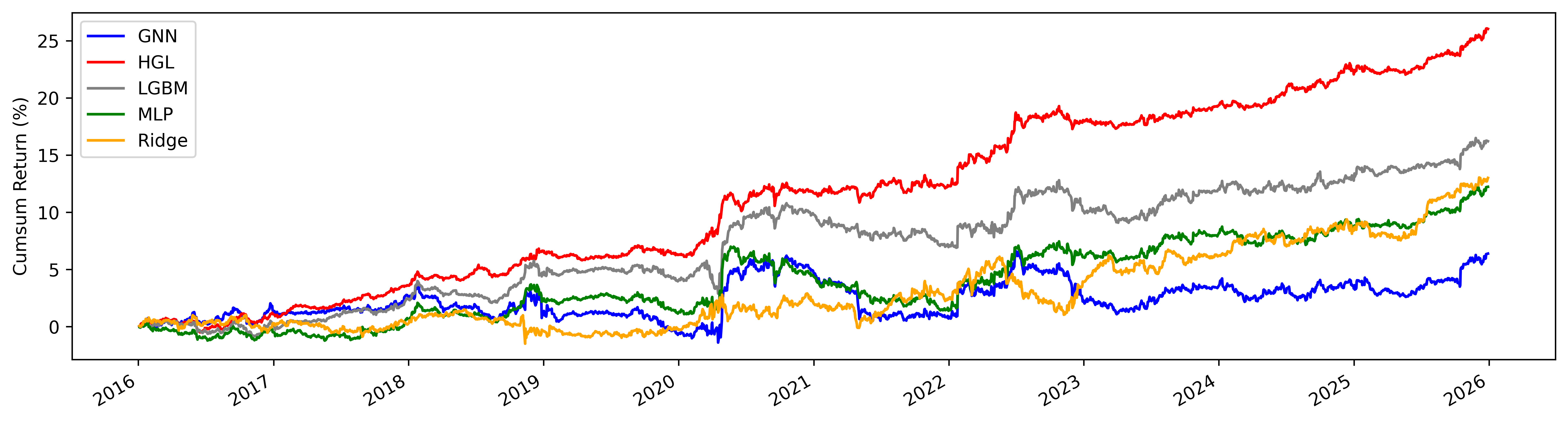
이 그래프에서 주목할 점은 2020년(COVID-19)과 2022년(러시아-우크라이나 전쟁) 구간입니다. 시장이 크게 출렁일 때 일시적으로 손실이 발생하지만, 빠르게 회복하는 패턴을 보입니다. 캘린더 스프레드는 '절대 수익'을 추구하는 전략이라 시장 전체의 방향보다는 상대 가격에 베팅하기 때문에, 이런 위기 상황에서도 상대적으로 회복력이 강합니다.
왜 캘린더 스프레드가 특별한가
이 논문에서 특히 흥미로운 발견은, 같은 전략이라도 캘린더 스프레드(CS)가 롱온리(LO)보다 훨씬 안정적이라는 점입니다:
- 변동성이 85% 낮습니다 (0.12% vs 0.78%)
- 최대 낙폭이 94% 낮습니다 (0.02 vs 0.35)
- S&P 500과의 상관관계가 -0.019로 거의 독립적입니다
쉽게 말하면, 주식시장이 오르든 내리든 이 전략은 자기 갈 길을 간다는 뜻입니다. 포트폴리오에 이런 전략을 넣으면 전체 위험을 줄이는 '분산 효과'를 기대할 수 있습니다.
한계와 주의점: 솔직하게 말씀드리면
좋은 소식만 있는 건 아닙니다. 이 연구의 한계도 분명히 있습니다:
-
가정에 의존합니다: 이론적 근거가 되는 '명제 1(Proposition 1)'이 특정 수학적 가정을 필요로 합니다. 실험에서 평균 81%의 경우가 이 가정을 만족하지만, 나머지 19%에서는 만족하지 않습니다.
-
일일 빈도 전략입니다: 하루에 한 번 포지션을 조정하는 전략이지, 초단타 매매가 아닙니다. 고빈도로 확장하려면 추가 연구가 필요합니다.
-
거래 비용이 있습니다: 하루 평균 포트폴리오 회전율이 55.7%입니다. 거래할 때마다 비용이 드니까, 이 비용을 빼고도 수익이 남는지 꼼꼼히 따져봐야 합니다.
-
상품선물에만 검증되었습니다: 주식, 채권 등 다른 자산군에서는 효과가 입증되지 않았습니다.
-
코드와 데이터가 공개되지 않았습니다: 논문에서 코드나 데이터셋 공개 계획을 언급하지 않아서, 직접 재현하려면 상당한 노력이 필요합니다.
그래서 투자/실무엔?
이 연구가 실제 투자에 주는 시사점을 정리하면:
첫째, 상품선물 시장에서 만기 구조를 명시적으로 모델링하는 것이 중요하다는 점을 보여줍니다. 같은 원유라도 3월물과 6월물은 다른 '동물'이라는 거죠. 이 인사이트는 상품선물뿐 아니라 채권, 금리 스왑 등 기간 구조가 있는 모든 자산에 적용 가능합니다.
둘째, 캘린더 스프레드 전략은 절대 수익과 리스크 관리 측면에서 매력적입니다. 시장 방향에 덜 의존하고, 변동성과 낙폭이 낮으므로, 포트폴리오의 '안전판' 역할을 기대할 수 있습니다.
셋째, 그래프 신경망(GNN)을 활용한 이 방법은 기존 규칙 기반 스프레드 전략을 데이터 기반으로 대체하거나 보완할 수 있는 프레임워크를 제공합니다. 다만, 코드가 공개되지 않았으니 직접 구현하려면 논문의 방법론을 참고해 비슷한 파이프라인을 만들어야 합니다.
더 알아보기
- 원 논문: Hierarchical Graph Learning for Calendar Spread Strategies in Commodity Futures Markets (arXiv:2606.25811)
- 저자: Yoonsik Hong, Diego Klabjan (Northwestern University)
관련 논문 더 보기
- The Inference-Compute Frontier for LOB Prediction — 호가창 예측의 스케일링 법칙
- Time-dependent Crypto Interaction Networks — 암호화폐 수익률의 시간가변 인과 네트워크
- Two-Stage ESG Long-Short Portfolio — ESG 인식 롱숏 포트폴리오
이 글은 arXiv 프리프린트(동료 검증 전)를 기반으로 작성되었습니다. 실험 결과는 특정 조건에서의 수치이며, 실제 투자 성과를 보장하지 않습니다.
참고: 이 글은 일반적인 정보 제공 목적이며, 구체적인 사안은 전문가와 상담하시기 바랍니다.
관련 글

포트폴리오가 '자신만만할수록 위험한' 이유 — 경로공간 베이지안 투자의 비밀
추정한 투자 전략이 얼마나 틀릴 수 있는지까지 감안하는 '강건한 베이지안 포트폴리오' 방법론을 일상 비유와 함께 쉽게 풀어 설명합니다.
AI가 주식을 예측할 때, '기억'하고 있었다면? — MemGuard-Alpha로 LLM 알파의 함정을 걸러내는 방법
대형 언어 모델(LLM)이 금융 데이터를 '기억'해서 만든 허위 알파 신호를 실시간으로 걸러내는 MemGuard-Alpha 프레임워크를 소개합니다. Sharpe 비율 49% 개선, 오염 신호 대비 7배 수익 차이의 핵심 원리를 쉽게 풀어 설명합니다.

AI가 투자 연구를 한다 — 오세랩 시스템 트레이딩 R&D 소개
오세에이아이연구소가 13개 연구 분과, 96편 논문으로 구축한 AI 기반 시스템 트레이딩 리서치 프레임워크를 소개합니다. 매일 자동 수집되는 논문에서 실전 투자 인사이트를 추출하는 과정을 공개합니다.