
120억 개 캔들차트로 배운 AI, 주식·비트코인·환율까지 꿰뚫다 — Kronos 파운데이션 모델
하나의 모델로 주식, 암호화폐, 외환, 선물까지 — 금융 시계열의 '범용 AI'가 등장했다.
들어가며
매일 아침 차트를 보신 적 있으신가요? 빨간색과 파란색 캔들이 위아래로 춤추는 모습, 투자자라면 누구나 익숙한 풍경입니다. 이 캔들 하나하나에는 시가, 고가, 저가, 종가, 거래량이라는 다섯 가지 숫자가 담겨 있습니다. 하루에만 전 세계 수천 개 종목에서 이런 캔들이 쏟아지니, 하루치 데이터만 해도 엄청난 양이죠.
그런데 이런 캔들차트 데이터를 120억 개나 모아서 AI에게 한꺼번에 가르친다면? 주식만이 아닙니다. 비트코인, 이더리움 같은 암호화폐부터 달러-원 환율, 심지어 철강 선물까지 — 45개 거래소의 데이터를 모두 합쳐서 하나의 거대한 모델을 만든 연구가 나왔습니다. 바로 Kronos입니다.
무엇이 문제였나
최근 인공지능 분야에서 '파운데이션 모델'이라는 개념이 화두입니다. GPT가 텍스트를, DALL-E가 그림을 하나의 큰 모델로 처리하듯, 금융 시계열에도 하나의 범용 모델이 있으면 좋겠다는 생각이 자연스럽습니다.
하지만 기존의 시계열 파운데이션 모델들은 금융 데이터에서 영 시원찮았습니다. 왜일까요?
첫째, 금융 데이터는 일반 시계열과 다릅니다. 주가 캔들은 단순한 숫자 나열이 아니라 가격 움직임과 거래 활동이 엮인 복합 구조입니다. 일반 시계열 모델이 이런 특성을 제대로 잡아내지 못했죠.
둘째, 기존 모델들은 주로 가격 예측만 다루었습니다. 하지만 실전에서는 변동성 예측도, 합성 데이터 생성도 필요합니다. 백테스트를 위한 가상 시나리오를 만들거나, 데이터가 부족한 종목의 패턴을 보강하려면 합성 데이터가 필수적이거든요.
셋째, 금융 데이터는 교차 자산 관계가 중요합니다. 미국 주식의 움직임이 아시아 시장에 영향을 미치고, 비트코인이 나스닥과 동조하는 현상처럼 — 서로 다른 시장의 패턴을 연결하는 능력이 필요합니다.
핵심 아이디어: 캔들차트를 '단어'로 만들다
Kronos의 핵심 아이디어는 간단하면서도 강력합니다. 바로 K-line(캔들차트) 데이터를 토큰으로 변환하는 것입니다.
텍스트 AI가 '안녕하세요'를 ['안', '녕', '하', '세', '요']로 쪼개듯, Kronos는 캔들차트 하나를 계층적 토큰으로 바꿉니다. 거친 토큰(coarse)은 큰 방향을, 세밀한 토큰(fine)은 디테일을 담당합니다. 이렇게 하면 가격 움직임의 큰 흐름과 작은 변동을 모두 포착할 수 있죠.
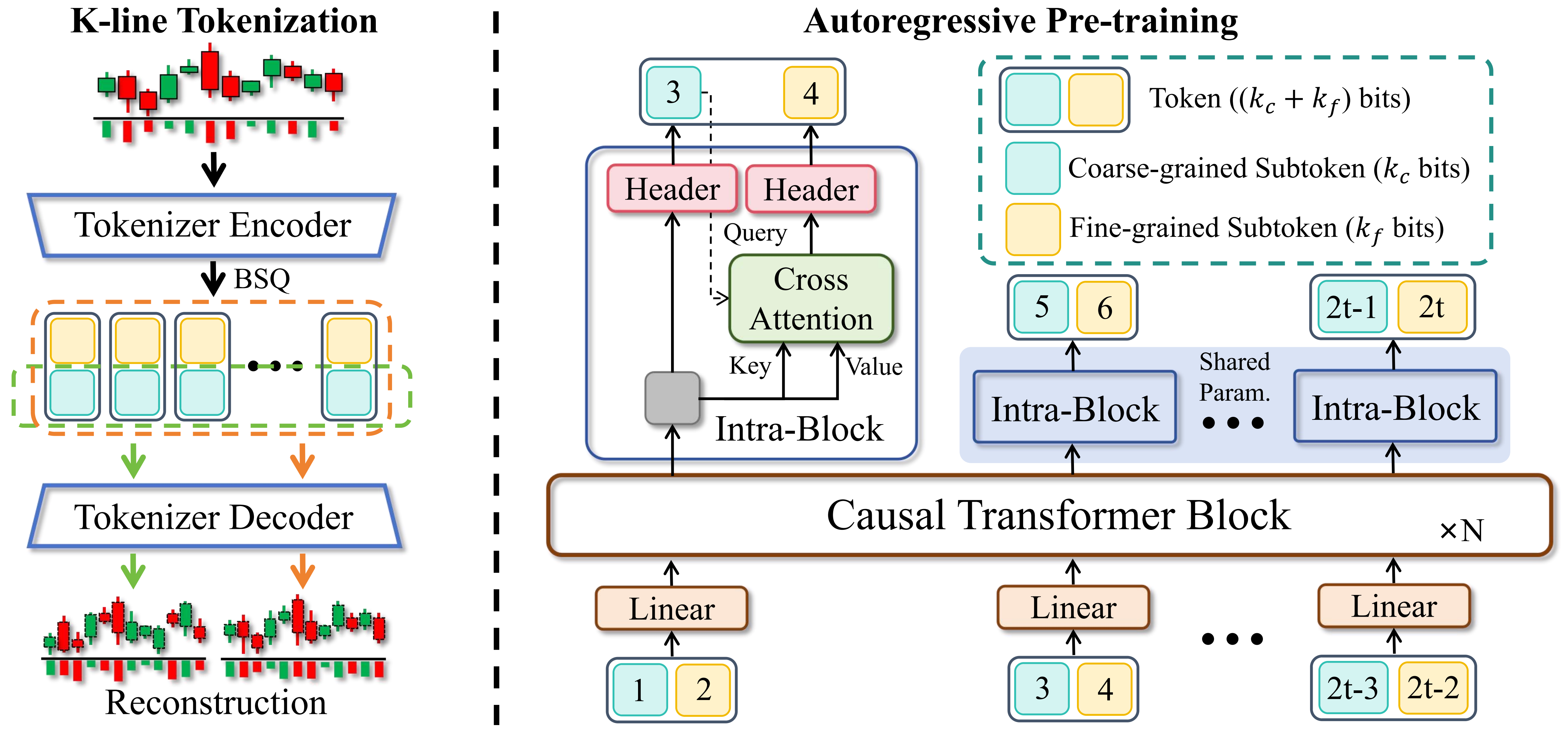
이 토큰화 과정은 Transformer 기반 자동인코더로 구현됩니다. 이진 구형 양자화(Binary Spherical Quantization, BSQ)라는 기법을 써서, 연속적인 시장 정보를 손실 최소화하면서 이산 토큰으로 변환합니다. 쉽게 말하면, 캔들차트의 '생김새'를 분류하는 아주 정밀한 분류기를 만든 셈이죠.
이렇게 토큰화된 시퀀스는 자기회귀(autoregressive) 방식으로 사전학습됩니다. GPT가 문장의 다음 단어를 예측하듯, Kronos는 캔들 시퀀스의 다음 캔들을 예측하면서 금융 시계열의 패턴을 학습합니다.
결과 — 무엇을 알아냈나
Kronos의 성과는 놀랍습니다. 학습에 사용된 데이터만 해도 120억 개 이상의 K-line 레코드, 전 세계 45개 거래소에서 수집한 것입니다. 주식, 암호화폐, 외환, 선물 등 자산 클래스도 다양합니다.
구체적인 수치를 보면:
-
가격 시계열 예측: 기존 최고 시계열 파운데이션 모델 대비 RankIC 93% 향상, 비사전학습 최고 기반선 대비 87% 향상. 이건 단순히 '좀 더 잘 맞힌다'가 아니라, 예측력의 질적 도약에 가깝습니다.
-
변동성 예측: MAE(평균절대오차)가 기존 대비 9% 낮아졌습니다. 변동성은 리스크 관리의 핵심이므로, 이 수치는 실전에서 직접적인 가치가 있습니다.
-
합성 데이터 생성: 합성 K-line 시퀀스의 생성 충실도가 22% 향상되었습니다. 만들어진 가짜 데이터가 실제 데이터와 얼마나 비슷한지를 측정하는 지표인데, 백테스트용 시나리오 생성의 품질이 크게 개선된다는 뜻입니다.
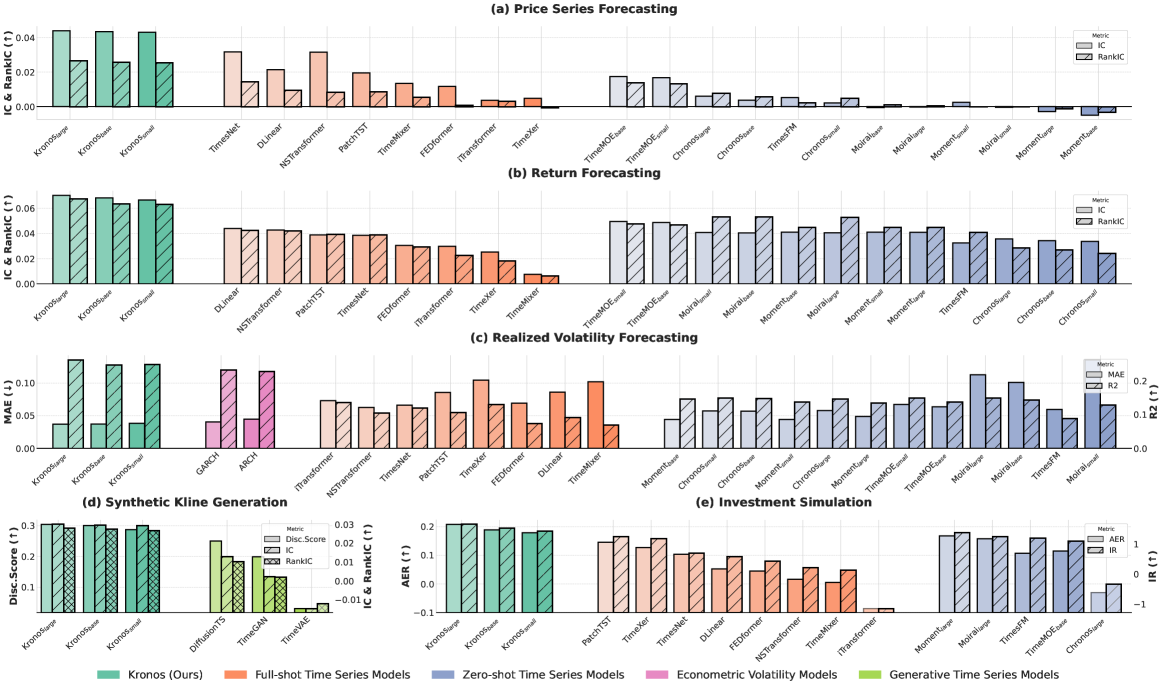
가장 인상적인 점은 제로샷(zero-shot) 성능입니다. 특정 종목이나 시장에 대해 추가 학습 없이도, 사전학습만으로 다양한 예측 태스크를 수행할 수 있다는 뜻입니다. 마치 GPT가 특정 분야의 책을 읽지 않았어도 그 분야에 대해 대화할 수 있는 것과 같은 원리죠.
한계와 주의점
물론 만능은 아닙니다.
첫째, 120억 개 K-line의 사전학습은 비용이 큽니다. 대규모 GPU 클러스터와 데이터 인프라가 필요합니다. 연구팀이 공개한 모델을 사용할 수 있지만, 자체적으로 재학습하거나 커스터마이징하기는 부담스러울 수 있습니다.
둘째, 모든 시장에서 동일하게 잘 작동하는지는 아직 검증이 필요합니다. 학습 데이터에 포함된 45개 거래소는 광범위하지만, 학습에 포함되지 않은 소규모 시장이나 이례적 레짐(예: 전쟁, 극단적 유동성 위기)에서의 성능은 아직 알려지지 않았습니다.
셋째, 예측력이 곧 수익을 보장하지는 않습니다. 좋은 예측 모델이 있어도 실행 비용, 시장 충격, 슬리피지 등을 고려해야 실제 수익으로 이어집니다. Kronos는 '예측 도구'이지 '트레이딩 전략'이 아니라는 점을 명심해야 합니다.
그래서 투자/실무엔?
Kronos가 제시하는 가능성은 세 가지 방향입니다.
첫째, 크로스자산 알파 발굴. 여러 시장의 패턴을 하나의 모델로 이해하므로, 서로 다른 자산 간의 숨겨진 관계를 발견하는 데 유용합니다. 예를 들어, 아시아 야간 선물 움직임이 미국 주식의 다음날 시가를 예측하는 패턴 같은 것을 자동으로 포착할 수 있겠죠.
둘째, 변동성 예측 고도화. 기존 GARCH 계열 모델이나 단순 역사적 변동성 대비, 훨씬 풍부한 정보를 반영한 변동성 추정이 가능합니다. 옵션 프라이싱이나 리스크 관리에서 직접 활용할 수 있습니다.
셋째, 합성 데이터 생성. 백테스트에 필요한 가상 시나리오, 스트레스 테스트용 데이터, 데이터 증강 등에 Kronos가 생성하는 합성 K-line을 사용할 수 있습니다. 실제 시장 통계 특성을 잘 보존하는 합성 데이터는 전략 검증의 신뢰도를 크게 높여줍니다.
함께하기
퀀트 투자와 AI 기반 금융 분석에 관심이 있으시다면, 저희와 함께 최신 연구를 따라가 보세요.
- 🌐 ohselab.com — 연구 소개 및 상담
- 📧 뉴스레터 구독 — 최신 논문 분석을 메일로 받아보세요
- 🐦 팔로우 — 실시간 시장 인사이트 공유
더 알아보기
- 📄 원 논문: arXiv:2508.02739
- 💻 코드: GitHub — shiyu-coder/Kronos
5차원 평가 점수 (KB 기준):
| 항목 | 점수 |
|---|---|
| 참신성 (Novelty) | 82 |
| 실용성 (Applicability) | 84 |
| 엄밀성 (Rigor) | 72 |
| 재현성 (Reproducibility) | 78 |
| 통찰력 (Insight) | 76 |
| 종합 (Composite) | 79.2 |
관련 논문:
- CTBench (2508.02758) — 암호화폐 합성 시계열 벤치마크
- ByteGen (2508.02247) — 오더북 이벤트 생성 모델
- Time-Varying Factor-Augmented Models (2508.01880) — 시변 팩터 변동성 예측
관련 글

2025년 8월 AI 트레이딩 연구 한눈에 보기: 금융 데이터에 특화된 AI가 온다
2025년 8월 arXiv에서 발굴한 AI 트레이딩·퀀트 투자 논문 170편을 5개 연구 테마로 정리. 금융 K-line 파운데이션 모델 Kronos, AMM의 LVR을 옵션 이론으로 재해석, 의사결정 직접 최적화 공분산 추정, LLM의 위치 편향 메커니즘 감사, 크립토 시계열 생성 벤치마크까지.
AI가 주식을 예측할 때, '기억'하고 있었다면? — MemGuard-Alpha로 LLM 알파의 함정을 걸러내는 방법
대형 언어 모델(LLM)이 금융 데이터를 '기억'해서 만든 허위 알파 신호를 실시간으로 걸러내는 MemGuard-Alpha 프레임워크를 소개합니다. Sharpe 비율 49% 개선, 오염 신호 대비 7배 수익 차이의 핵심 원리를 쉽게 풀어 설명합니다.

2026년 6월 AI 트레이딩 연구 한눈에 보기: 이론과 실무를 꿰매는 달
2026년 6월 arXiv에서 발굴한 AI 트레이딩·퀀트 투자 논문 151편을 5개 연구 테마로 정리. AMM 수수료 최적 제어, 신경망 옵션 가격의 오차 상계, LLM 자산 편향 감사, 기관 포트폴리오 GPU 가속, 강화학습의 경제적 해석까지.