
논문 속 숫자를 의심하라 — 2026년 3월 시스템 트레이딩 연구 월간 종합
"같은 전략, 같은 데이터인데 왜 결과가 다를까요?"
이 한 가지 질문에, 2026년 3월에 올라온 수백 편의 논문이 저마다의 방향에서 답을 내놓았습니다. 백테스트 엔진을 바꿔 돌렸더니 수익률이 달라졌고, 인공지능이 미래 정보를 이미 알고 있었으며, 로봇 트레이더의 화려한 성적이 현실에서는 거짓말이었습니다. 이달의 키워드는 단 하나: 현실 괴리(reality gap) 줄이기입니다.
들어가며: 비행 시뮬레이터와 실제 비행의 차이
비행 시뮬레이터는 실제 비행과 거의 비슷하지만, 완전히 같지는 않습니다. 바람이 부는 방식, 조종간의 미세한 저항, 기체가 흔들리는 감촉 — 이런 것들은 시뮬레이터가 제대로 재현하지 못합니다. 그런데 만약 파일럿이 시뮬레이터에서만 훈련하고 실제 비행에 올랐다면? 결과는 불 보듯 뻔합니다.
시스템 트레이딩의 세계도 비슷합니다. 우리는 컴퓨터 안에서 전략을 시뮬레이션(백테스트)으로 검증하고, 그 결과가 좋으면 실제 시장에 돈을 겁니다. 그런데 이 시뮬레이션이 실제 시장을 얼마나 정직하게 재현하고 있을까요? 2026년 3월, 연구자들은 이 질문을 다섯 가지 각도에서 정면으로 파고들었습니다.
이번 달 우리가 수집·평가한 논문은 734건. 그중 223건(30.4%)이 실제 투자 연구와 관련 있었고, 최고 등급(A등급) 논문은 33건이었습니다. 이 33건을 다섯 가지 연구 테마로 묵어 하나씩 살펴보겠습니다.
테마 1: 백테스트 엔진을 바꾸면 결과가 달라진다
비유: 레시피는 같은데 주방이 다르면 요리가 달라지는 것
같은 재료, 같은 레시피인데 주방(오븐, 프라이팬, 가스레인지)이 다르면 요리 맛이 달라집니다. 백테스트도 같습니다. 전략 로직은 같지만, 수익을 계산하는 소프트웨어 엔진이 다르면 결과 숫자가 달라질 수 있다는 겁니다.
대표 논문: Implementation Risk in Portfolio Backtesting
arXiv: 2603.20319 · 등급 A · 종합 78.7점
이 논문은 "구현 리스크(implementation risk)"라는 개념을 새로 정의합니다. 쉽게 말하면, 같은 전략이라도 어떤 소프트웨어로 돌리느냐에 따라 수익률이 달라지는 오차를 말합니다.
연구팀은 오픈소스 백테스트 엔진 5개를 골라, 벤치마크 전략 15개, S&P 500 종목 180개, 거래비용 시나리오 4가지로 대규모 실험을 했습니다.
핵심 결과를 보면:
- 거래비용이 0일 때는 엔진 5개가 완전히 같은 결과를 냅니다(발산 0.000%p).
- 대부분 전략에서는 엔진 간 차이가 0.75%p 미만으로 작았습니다.
- 하지만 회전율이 높은 전략(로테이션 전략)에서는 최대 3.71%p까지 벌어졌습니다.
- 이 차이를 만드는 거의 유일한 원인은 거래비용 계산 방식이었습니다(상관관계 ρ=0.93,
p<0.001).
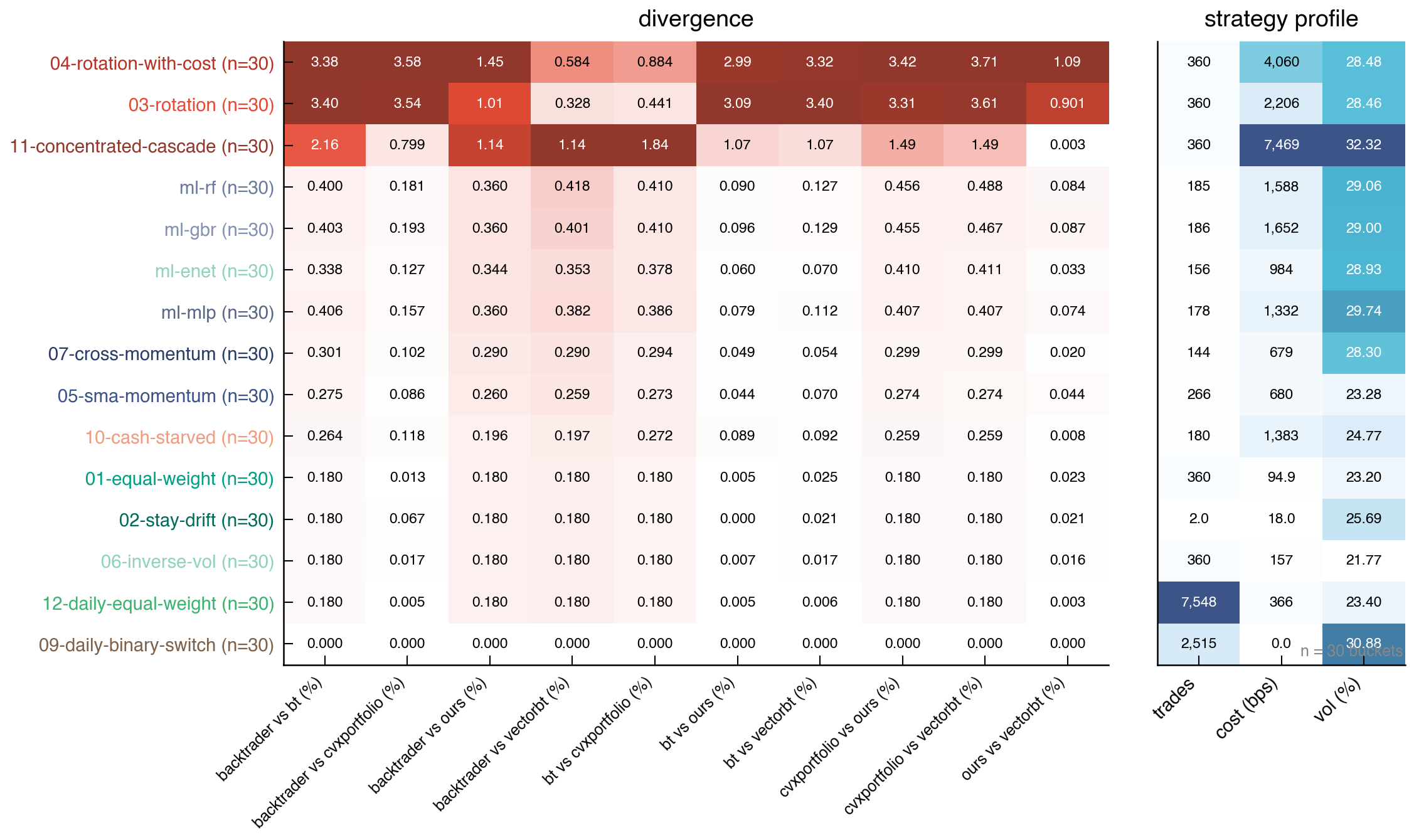
흥미로운 점은, 엔진 간 수익률 차이가 컸음에도 불구하고, 전략 간 우위(어떤 전략이 더 좋은지)는 엔진 5개가 모두 동의했다는 것입니다. 즉, "전략 A가 전략 B보다 낫다"는 결론은 엔진에 상관없이 같았지만, "정확히 얼마나 더 낫냐"는 숫자는 달랐습니다.
다만, 이 결론은 S&P 500 롱온리 전략에 한정됩니다. 고빈도 거래, 파생상품, 레버리지까지 가면 차이가 더 커질 수 있습니다.
함께 본 논문들
- MemGuard-Alpha (2603.26797): 인공지능이 만든 투자 신호에서 "정말로 예측한 것"과 "학습 데이터에서 기억한 것"을 분리해내는 필터. 시점 정보 누수를 사전에 거르는 파이프라인입니다.
- ERP-RiskBench (2603.06671): 금융 리스크 탐지 벤치마크인데, 핵심은 "데이터 누수(leakage)를 막아야 평가가 의미 있다"는 메시지입니다.
이 테마의 공통 인사이트
같은 전략·같은 데이터인데 결과가 다른 이유는? 엔진 구현 차이, LLM 신호의 기억 오염, 평가 단계의 데이터 누수 — 셋 모두 "백테스트 숫자가 진짜인지 의심하라"는 같은 경고를 다른 각도에서 합니다.
테마 2: 인공지능 트레이딩 에이전트의 "시간 여행" 문제
비유: 내일 신문을 이미 읽은 예언자에게 투자 조언을 구하는 것
상상해 보세요. 누군가에게 주식 투자 조언을 구했는데, 그 사람이 이미 내일 신문을 읽었다면? 그 조언은 "실력"이 아니라 "부정행위"에 가깝습니다. 대형 언어 모델(LLM)로 금융 백테스트를 할 때도 비슷한 문제가 생깁니다. 2024년까지 학습한 모델에게 "2020년 기준으로 투자해 보세요"라고 하면, 모델은 이미 2021~2024년의 사건을 알고 있는 상태에서 판단하게 됩니다. 이것을 룩어헤드 바이어스(lookahead bias) — "미래를 미리 보는 편향" — 라고 합니다.
대표 논문: DatedGPT — Time-Aware Pretraining
arXiv: 2603.11838 · 등급 A · 종합 75.0점
이 연구는 문제를 근본적으로 해결합니다. 아예 2013년부터 2024년까지, 연도별로 12개의 별도 모델을 처음부터 새로 학습시킵니다. 2020년 컷오프 모델은 2020년 데이터까지만 본 상태이므로, ChatGPT가 뭔지 모릅니다. 2017년 컷오프 모델은 그 이전까지만 알죠.
구체적으로:
- 1.3B(13억) 파라미터 모델을 12개 만듭니다(연도별 하나씩).
- 각 모델은 약 1,000억 개 토큰으로 학습합니다.
- 퍼플렉서티(언어 모델의 "확신도") 검사 결과, 각 모델의 지식이 실제로 지정된 연도에 묶여 있음을 확인했습니다.
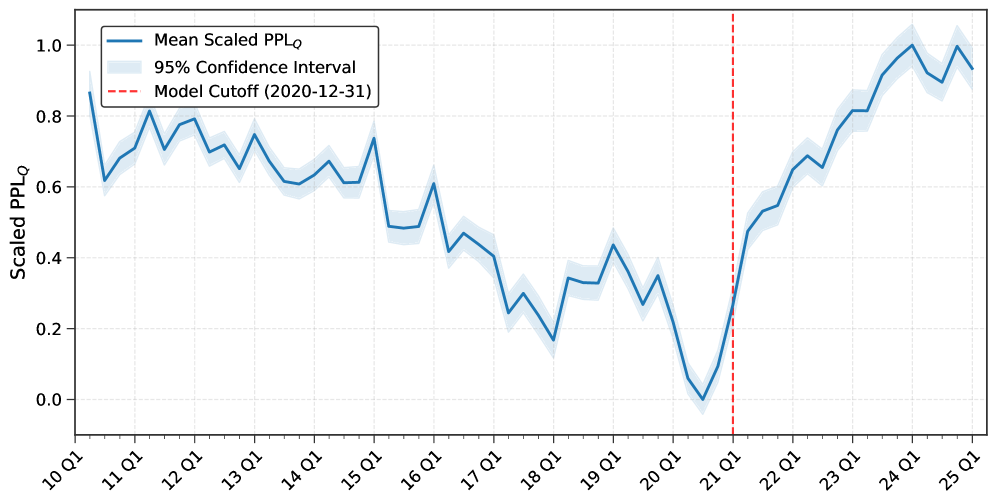
기존 동급 규모 모델과 비교해도 일반 언어 성능이 크게 떨어지지 않으면서 시점 차단을 달성했습니다.
다만, 실제 투자 수익 성능 비교가 아직 제한적이고, 12개 모델을 처음부터 학습하는 비용이 매우 크다는 점은 한계입니다.
함께 본 논문들
- TraderBench (2603.00285): 적대적 거래 시뮬레이션을 결합해 AI 에이전트의 "실전 강건성"을 성과 기반으로 평가하는 벤치마크입니다.
- Unlocking Data Value in Finance (2603.07223): 금융 LLM의 수치 추론 능력을 데이터 품질 개선으로 끌어올리는 연구입니다.
이 테마의 공통 인사이트
LLM을 트레이딩에 쓸 때 가장 무서운 적은 성능이 아니라 "미래를 이미 알고 있는 모델"입니다. 시점 누수를 사전학습 단계에서 차단하거나, 적대적 시장에서 강건성을 측정하거나, 데이터 품질로 신뢰를 확보하려는 흐름이 함께 갑니다.
테마 3: 강화학습 트레이딩의 "공중에서의 현실"
비유: 수영장에서 잘하는데 바다에 뛰어든 것
강화학습(RL)으로 트레이딩 전략을 만들면, 백테스트에서는 놀라운 수익률을 보여주는 경우가 많습니다. 하지만 이것은 수영장(통제된 환경)에서의 성적입니다. 실제 바다(시장)에는 파도(시장 충격), 조류(유동성 변화), 해파리(거래비용)가 있습니다. 수영장 실력이 바다에서도 통할까요?
대표 논문: Realistic Market Impact Modeling for RL Trading Environments
arXiv: 2603.29086 · 등급 A · 종합 69.7점
이 논문은 현실적인 시장 충격 모델을 넣었을 때 RL 에이전트의 행동이 어떻게 바뀌는지 측정합니다. 핵심은 Almgren-Chriss 프레임워크와 경험적으로 검증된 제곱근 충격 법칙(square-root impact law)을 적용한 것입니다.
실험은 NASDAQ-100 데이터로 RL 에이전트 5종(A2C, PPO, DDPG, SAC, TD3)을 비교했습니다.
놀라운 결과:
- 현실적 충격 모델을 넣자 일일 거래비용이
$200,000에서$8,000로 급감했습니다. 에이전트가 과도매매를 멈춘 겁니다. - 회전율이 19%에서 1%로 떨어졌습니다.
- 알고리즘 간 순위가 통째로 뒤집혔습니다: 마진 트레이딩에서 DDPG는 -2.1에서 0.3으로 개선됐지만, SAC는 -0.5에서 -1.2로 악화됐습니다.
- 하이퍼파라미터 최적화로 비용을 최대 82% 추가 절감했습니다.
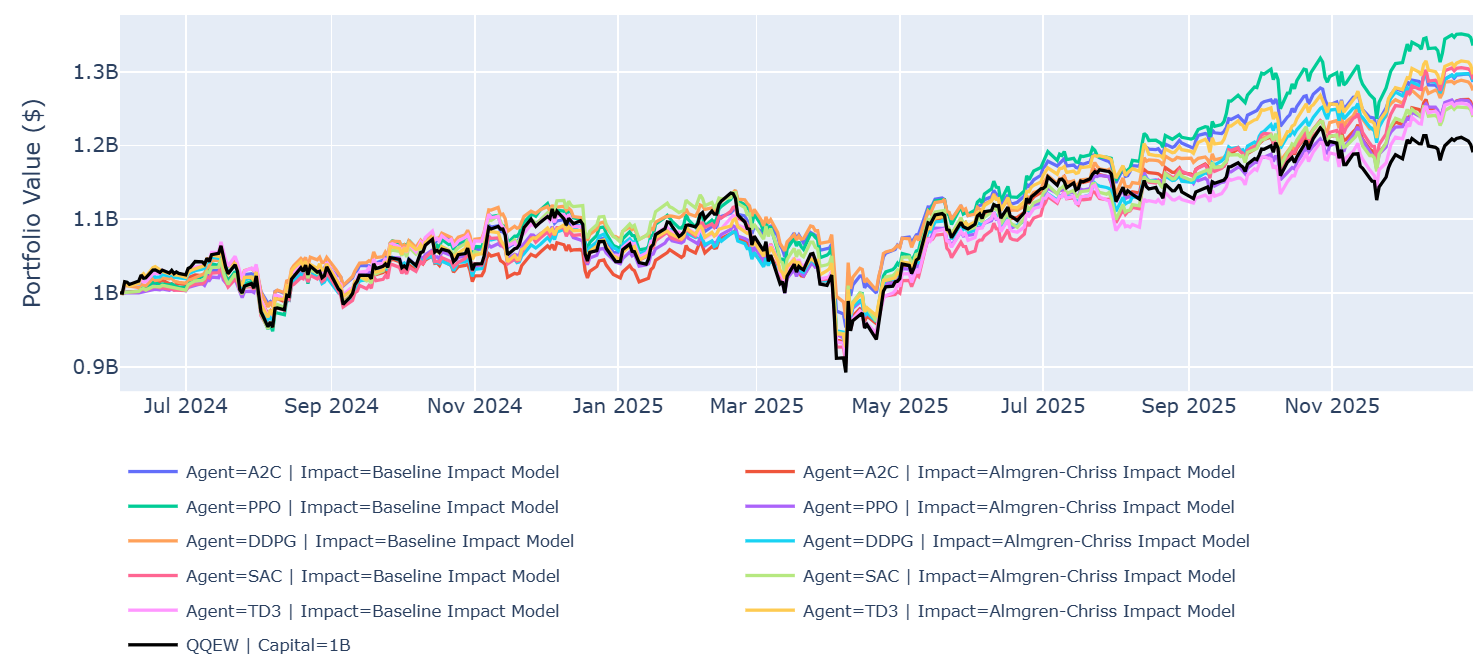
쉽게 말하면, 고정된 거래비용으로 학습한 RL 정책은 신뢰하면 안 된다는 뜻입니다. 현실적 충격을 반영하자 에이전트가 "매매를 줄이는 쪽으로" 적응했고, 그 결과 성능과 순위가 모두 바뀌었습니다.
함께 본 논문들
- FinRL-X (2603.21330): 리서치 평가와 라이브 배포를 하나의 파이프라인으로 잇는 인프라. 백테스트와 실제 거래의 시스템 불일치를 줄이려는 시도입니다.
- Conformal Policy Control (2603.02196): 컨포멀 예측으로 탐색에 확률적 안전 제약을 거는 안전 강화학습입니다.
이 테마의 공통 인사이트
강화학습 트레이딩의 화려한 백테스트 수익은 대개 "비현실적 체결 가정" 위에 서 있습니다. 현실적 시장충격과 비용을 넣으면 성능과 알고리즘 순위가 통째로 뒤집힙니다.
테마 4: 어떻게 체결되느냐가 곧 수익이다 — MEV와 시장 설계
비유: 경매에서 "비공개 입찰"과 "공개 입찰"의 차이
집을 살 때 생각해 보세요. 비공개 입찰에서는 다른 사람이 얼마를 썼는지 모르고, 공개 입찰에서는 알 수 있습니다. 어느 쪽이 집을 파는 사람에게 유리할까요? 직관적으로는 비공개가 나을 것 같지만, 실제로는 공개 입찰이 더 높은 가격을 가져오는 경우가 많습니다.
블록체인 세계에서도 비슷한 문제가 있습니다. MEV(Maximum Extractable Value) — 트랜잭션 순서를 바꿔서 추출할 수 있는 가치 — 를 놓고 경매가 벌어지는데, 이 경매를 어떤 방식으로 설계하느냐에 따라 수익이 크게 달라집니다.
대표 논문: Open vs. Sealed — Auction Format Choice for MEV
arXiv: 2603.16333 · 등급 A · 종합 71.0점
이 논문은 이더리움 트랜잭션 약 220만 건을 분석해, MEV 경매에서 공개형(영국식 오름·네덜란드식 내림)과 비공개형(봉인입찰) 포맷의 수익 차이를 실증했습니다.
핵심 수치:
- 중간 상관(ρ=0.5) 조건에서 공개형이 비공개형보다 14~28% 더 높은 수익을 냈습니다.
- 입찰자 수가 적을 때는 차이가 최대 약 30%까지 벌어졌습니다.
- 표본 기간 동안 비공개형을 선택한 것은 **
$10~18M(약 130억~234억 원)**의 수익을 포기한 셈입니다.
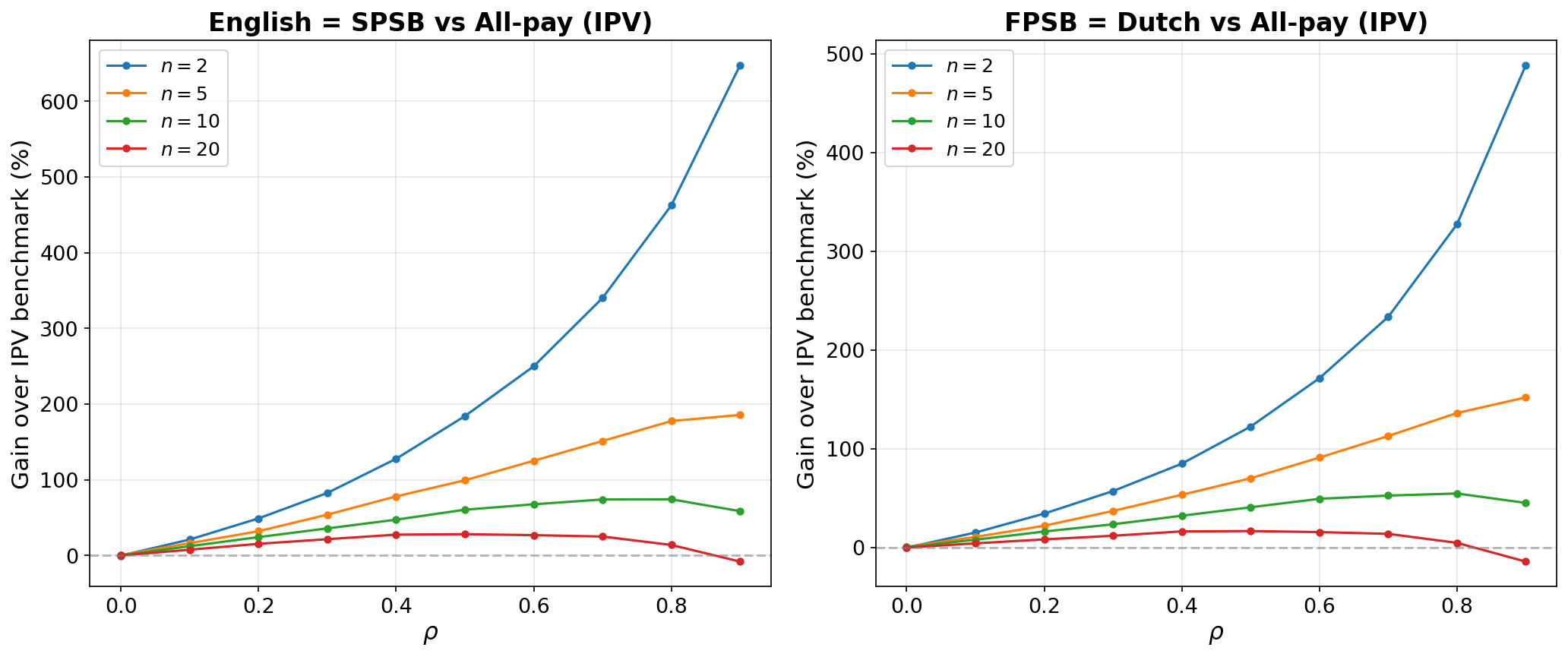
핵심 메시지는 단순합니다: 비공개 라우팅이 항상 유리한 것은 아니며, 참여자들 간 가치가 서로 관련될수록 투명한 경매가 더 나은 가격을 줄 수 있다는 겁니다.
다만, 이 결론은 크립토 MEV 시장 특수성이 강해 전통 자산 실행에 직접 일반화하기는 신중해야 합니다.
함께 본 논문들
- Bridging the Reality Gap in LOB Simulation (2603.24137): 대형 호가창을 현실적 체결·비용까지 재현하는 인터랙티브 시뮬레이터입니다.
- Risk-Based Auto-Deleveraging (2603.15963): 자동 청산의 손실 사회화를 리스크 기반으로 설계하는 거래소 리스크 관리 연구입니다.
이 테마의 공통 인사이트
"어디서 어떻게 체결되는가"가 곧 수익입니다. 경매 포맷 설계, 호가창 시뮬레이션의 현실성, 청산·리스크 관리 — 모두 실행 인프라의 미세 설계가 슬리피지·수익 배분·꼬리 리스크를 가른다고 말합니다.
테마 5: 거래비용이 있으면 교과서 헤징은 무너진다
비유: 우산이 있는데 비가 올 때마다 우산을 사고팔아야 한다면?
옵션을 보유한 뒤 리스크를 없애려면(헷징하려면) 주식을 계속 사고팔아야 합니다. 교과서에서는 이 과정이 "무비용"이라고 가정하지만, 현실에는 거래비용이 있습니다. 비가 올 때마다 우산을 사고팔아야 한다면, 우산 값(거래비용)이 비를 맞는 손실보다 더 클 수 있습니다.
대표 논문: Bridging Stochastic Control and Deep Hedging
arXiv: 2603.29994 · 등급 A · 종합 67.1점
이 논문은 두 가지 프레임워크를 잇습니다. 하나는 확률적 최적제어 — 수학적으로 엄밀하게 거래비용 하의 최적 헤징 비율을 구하는 이론. 다른 하나는 딥헤징 — 신경망으로 헤징 전략을 데이터 기반으로 학습하는 방법.
연구팀은 이론에서 나온 "무거래 밴드(no-transaction band)" — 이 좁은 영역 안에서는 매매하지 않고, 밖에서만 조절하는 최적 전략 — 를 신경망의 구조적 사전지식으로 넣었습니다(WW-NTBN).
핵심 결과:
- WW-NTBN이 더 빠르게 수렴하고, 이론적 최적 해에 더 가깝게 일치했습니다.
- 거래비용이 커질수록 매도자·매수자 무차별 가격 차이(bid-ask spread)가 벌어지는 구조를 재현했습니다.
- 불 콜 스프레드 같은 복합 파생에서는 거래비용 하의 가격 선형성이 깨진다는 점을 드러냈습니다.
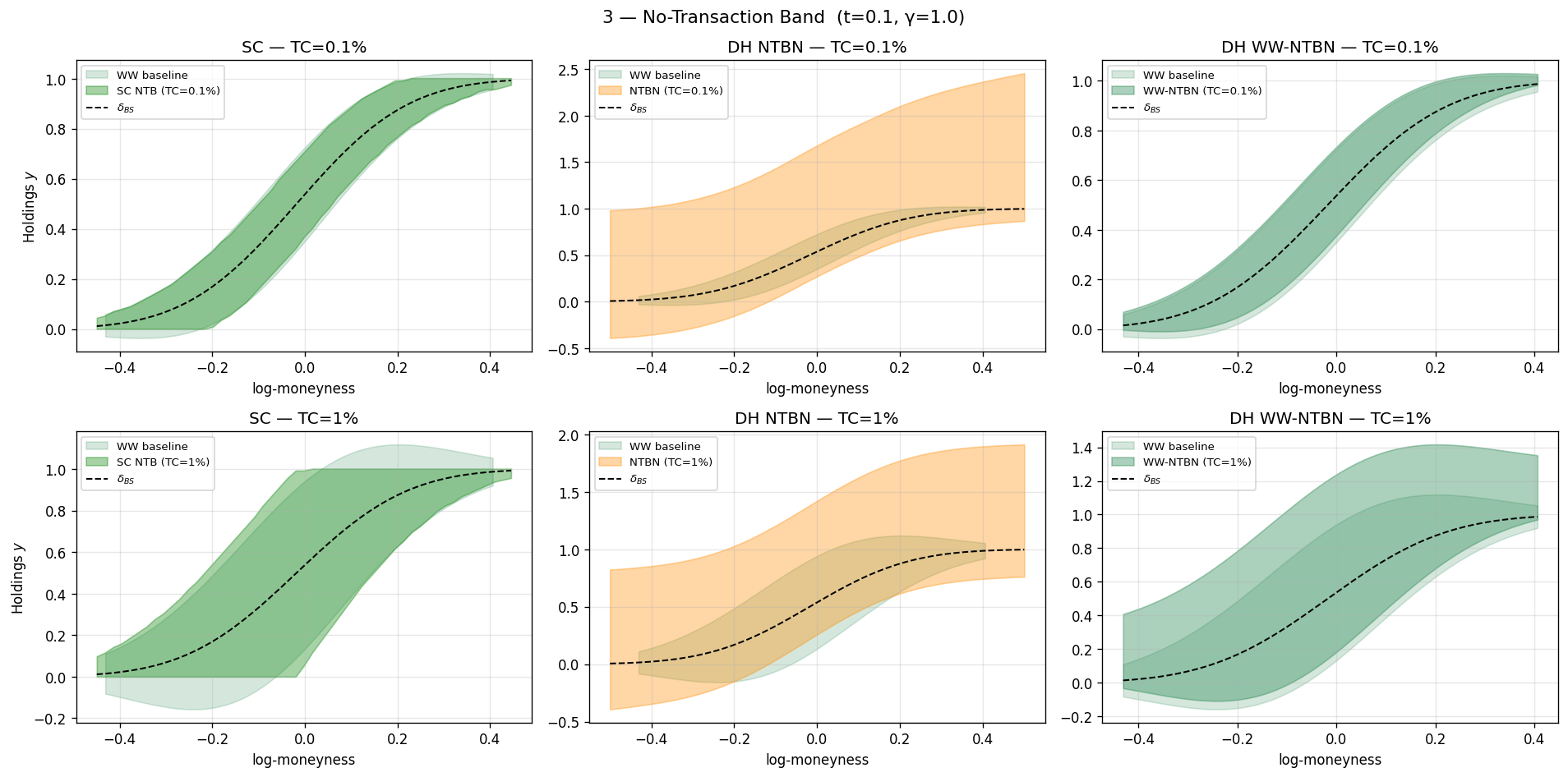
쉽게 말하면, 데이터로만 학습한 딥헤징보다, 검증된 이론(무거래 밴드)을 구조적 사전지식으로 주입하면 적은 데이터로도 안정적이고 해석 가능한 헤징 정책을 얻는다는 설계 원칙을 제시합니다.
함께 본 논문들
- Uncertainty-Aware Deep Hedging (2603.10137): 딥 앙상블과 LSTM으로 헤지 비율의 불확실성을 정량화해 모델 신뢰도를 함께 출력합니다.
- Semi-Static Variance-Optimal Hedging (2603.25320): 다자산 파생의 공분산·상관 리스크를 반정적 헤징으로 분산-최적화합니다.
이 테마의 공통 인사이트
거래비용이 있으면 교과서 델타 헤징은 무너집니다. 이론의 구조적 사전지식을 딥러닝에 주입하거나, 불확실성을 정량화하거나, 공분산 리스크를 반정적으로 헤징하려는 흐름이 "비용 하의 현실적 헤징"으로 수렴합니다.
월 전체 Big Picture: "더 화려한 수익"이 아니라 "덜 거짓말하는 검증"
2603 코호트를 관통하는 한 단락 메시지는 이것입니다:
"논문상 숫자를 의심하고, 현실 괴리를 정직하게 메워라."
다섯 테마는 표면적으로 백테스트 엔진, LLM, 강화학습, MEV 경매, 옵션 헤징으로 흩어져 있지만, 전부 같은 질문 — "내 시뮬레이션이 실거래를 얼마나 속이고 있는가?" — 을 던집니다.
| 테마 | 현실 괴리의 원인 | 공통 처방 |
|---|---|---|
| T1 백테스트 신뢰성 | 엔진 구현 차이 | 비용 모델을 명시적으로 명세화 |
| T2 LLM 시점 누수 | 미래 정보 유입 | 시점 컷오프를 학습 단계에서 차단 |
| T3 RL 실행 현실성 | 비현실적 체결 가정 | 현실적 충격 모델을 환경에 포함 |
| T4 시장 미시구조 | 실행 인프라 설계 | 포맷·투명성이 실행 품질을 결정 |
| T5 옵션 헤징 | 거래비용 가정 | 이론을 구조적 사전지식으로 활용 |
공통 처방도 일치합니다:
- 비용·마찰·시점을 명시적으로 모델링하고,
- 단일 엔진·단일 가정에 의존하지 말며,
- 검증된 이론을 구조적 사전지식으로 활용하라.
이번 달 코호트는 "더 화려한 수익"이 아니라 "덜 거짓말하는 검증"을 만드는 쪽으로 무게가 실려 있습니다.
함께하기
이런 연구를 꾸준히 읽고 실무에 적용하고 싶으시다면:
- 뉴스레터 구독: 최신 논문 분석을 매주 받아보세요 → ohselab.com
- 상담 문의: 퀀트 전략 수립·검증이 필요하시다면 → ohselab.com
- 팔로우: 소셜 미디어에서 최신 소식을 빠르게 → ohselab.com
더 알아보기
이 글에서 다룬 대표 논문들의 arXiv 링크입니다:
- Implementation Risk in Portfolio Backtesting — arXiv:2603.20319
- DatedGPT: Preventing Lookahead Bias — arXiv:2603.11838
- TraderBench — arXiv:2603.00285
- Realistic Market Impact for RL Trading — arXiv:2603.29086
- Open vs. Sealed: Auction Format for MEV — arXiv:2603.16333
- Bridging Stochastic Control and Deep Hedging — arXiv:2603.29994
이 글은 2026년 3월 arXiv에 공개된 734건의 시스템 트레이딩 관련 논문을 분석한 결과입니다. A등급 33건을 포함한 223건의 관련 논문을 5개 테마로 분류하고, 각 테마의 대표 논문을 깊이 있게 분석했습니다. 모든 수치와 주장은 원문 논문에 근거하고 있으며, 투자 권유가 아닌 연구 분석 자료입니다.
관련 글

AI가 투자 연구를 한다 — 오세랩 시스템 트레이딩 R&D 소개
오세에이아이연구소가 13개 연구 분과, 96편 논문으로 구축한 AI 기반 시스템 트레이딩 리서치 프레임워크를 소개합니다. 매일 자동 수집되는 논문에서 실전 투자 인사이트를 추출하는 과정을 공개합니다.

수익을 자랑하기 전에, 그 수익이 진짜인지 증명하라 — 2026년 4월 시스템 트레이딩 연구 월간 종합
2026년 4월 arXiv에 공개된 716편의 금융 AI 논문 중 252편을 분석한 월간 종합 리포트. 백테스트 검증, LLM 에이전트, 포트폴리오 최적화, 시장 미시구조, 옵션·파생까지 다섯 가지 연구 테마를 살펴봅니다.

성과를 만드는 것보다 검증하는 것이 더 중요해진 시대 — 2026년 5월 AI 퀀트 연구 월간 종합
2026년 5월에 발표된 AI 퀀트 연구 755편을 분석한 월간 종합. 백테스트 검증의 함정, LLM 트레이딩 에이전트의 감사가능성, 마켓메이킹의 리스크 민감 제어, 크립토 DeFi 미시구조, 옵션 변동성 딥헤징 등 5가지 테마를 친절하게 풀어낸다.